传统的高性能计算集群一般都习惯性地使用 Slurm + Lustre 的方案作为任务调度和存储,
然而,随着容器的发展,互联网业务的部署已经越来越多地开始了容器化,
而 Kubernetes 也成为了容器编排的事实标准。
而且,对比容器化的简洁, Slurm 和 Lustre 复杂的配置,让人头疼的运維压力,
也让作为互联网的最前沿之一的机器学习,也开始了容器化探索。
简介
本系列文章主要记录了在 Kubernetes 内使用 Pytorch 运行 ImageNet 的淌坑经验,
同时也使用 CephFS 作为网络存储,解决数据存放问题。
计划:
- 简介和容器内使用显卡(本文)
- Kuberentes 和 Device Plugin
- Kubeflow 和 Pytorch-Operator
- CSI(Cofntainer Storage Interface) 和 CephFS 网络存储
- mnist Demo 和分布式训练(MPI)
- 分布式 ImageNet
Slurm
Slurm(Simple Linux Utility for Resource Management) 是一个用于Linux 和 Unix 内核系统的免费、开源的任务调度工具, 被世界范围内的(包括天河等)超级计算机和计算机群广泛采用。
Slurm 的成熟度毋庸置疑,但是有两个问题:
- 在互联网公司不一定能有专人维护 Slurm 集群
- 交付环境没有 Slurm
Lustre
Lustre(得名于:Linux + Cluster) 一种平行分布式文件系统,通常用于大型计算机集群和超级计算机。 很多时候都是和 Slurm 配套使用的,所以也会有类似 Slurm 的两个问题。
Kubernetes + Ceph
互联网时代,容器化并使用 Kubernetes 同时使用 Ceph 作为网络存储肯定是毫无疑问的方案和方向。 如果 Kubernetes + Ceph 能够解决机器学习中高性能集群资源分配和利用的问题, 那对于互联网公司,肯定会是更好的选择。
容器内使用显卡
GPU
现在机器学习的主流是深度学习,自然 GPU 是少不了的。本文中使用了 Nvidia 的 GTX 1080Ti。
驱动
首先确认机器上是否有 GPU 卡:
lspci -vnn | grep NVIDIA
# Nvidia 显卡可以用自家工具看到详情
nvidia-smi
确认安装了 Nvidia 驱动 (cuda-driver),一般直接从源里安装即可。
如果官方源里没有,那就在 Nvidia 提供的这里下载安装文件,安装也可。
这里需要注意的是高版本的 CUDA 同样需要高版本的驱动,对应关系如下:
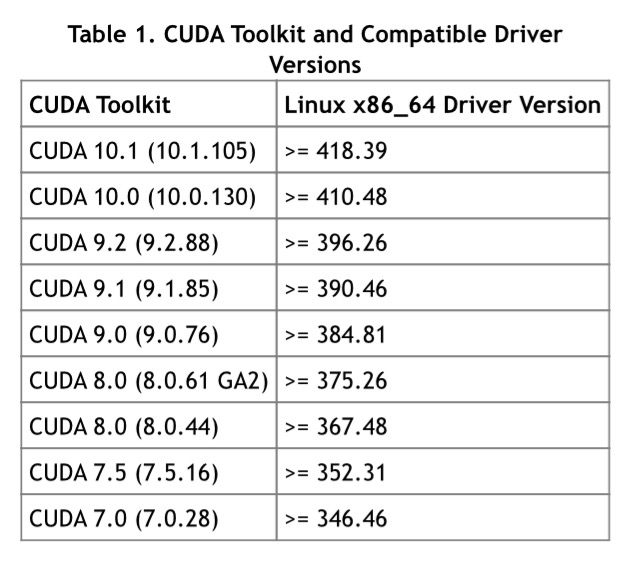{kind=link}
Nvidia docker 2.0
https://github.com/NVIDIA/nvidia-docker
默认的 Docker 是不支持 GPU 的,所以我们需要 nvidia-docker ,这是 Nvidia 为了支持 Docker 生态出的一个包,
而 nvidia docker 2.0 是第二版,主要是为 Docker 新增了一个 nvidia 的运行时,
所以在安装完 nvidia docker 2.0 后,需要把 Docker 的默认运行时个性为 nvidia 。
可以通过修改 docker 配置文件 /etc/docker/daemon.json 让 docker 能够使用 Nvidia Container Runtime
Nvidia Container Runtime 作为核心部分,在原有的容器运行时 runc 的基础上增加一个 prestart hook ,
用于调用 libnvidia-container 库。
libnvidia-container 提供一个库和一个简单的 Cli 工具,这个库让容器能够使用 Nvidia 的 GPU。
runc 是docker默认的容器运行时,根据 Open Containers Initiative (OCI) 创建容器。
总而言之,就是当我们要在 Docker 里使用 Nvidia GPU 时,就必须要安装 Nvidia Docker
安装完之后,基本的用法如下,可以测试一下:
docker run --runtime=nvidia --rm nvidia/cuda nvidia-smi
如果出现 brand = tesla: unknown 的错误,就是 cuda 的版本和我们使用的驱动不匹配,
可以看一下宿主显卡驱动的版本和使用的 CUDA 版本,然后对照上文的图片看是否匹配。
可以使用对应版本的 CUDA 镜像,如:
docker run --runtime=nvidia --rm nvidia/cuda:8.0-runtime nvidia-smi
也可以更新宿主机驱动。
至此,我们就可以在容器内使用 GPU 了,但是我们想在 Kubernetes 内使用,还需要使用 Device Plugin ,这个会在后文说到。